
垢を替え、ハンドルネームを作り、本名なんて一度も出さない。それで、自分は見つからないと思っていないだろうか。ネットの中に、あなたはいくつの垢を持っているだろう。掲示板では映画の点数をつけながら駄作に毒づくための垢がひとつ。知恵袋では、たまに専門っぽい話をして、ちょっと物知りな顔をするための垢がひとつ。Xには別の垢があって、職場の人には見られたくない愚痴や本音を流している。
かなり安全だと思っていませんか?。名前は作りもの、アイコンは適当に拾ったもの。住んでいる場所も、本名も、一度も書いたことがない。誰がわざわざ自分なんかを調べるのか。仮に本気で調べようとしても、何千件もの投稿を掘り返して、つじつまを照らし合わせて、複数のサイトを横断して確認していくなんて、人力ではあまりに面倒だ。手間も時間もかかる。だからこそ、見つからない。そう思っていた。
その安心感を、最近ある一本の論文が容赦なく打ち砕いた。

2026年2月、AI企業Anthropicとスイス連邦工科大学チューリッヒ校(ETH Zurich)の研究者たちが、ずいぶん露骨な題名の論文を発表した。タイトルは「Large-scale online deanonymization with LLMs」。つまり、大規模言語モデルを使って、オンライン上の匿名ユーザーを実在の人物へ結びつける、という話である。もっと平たく言えば、AIを使って、ネット上の匿名アカウントと現実の人間を照合する研究だ。
しかも、そのために必要なコストはわずか1〜4ドル。だいたいコーヒー一杯分の値段である。
まず、この実験がどのように行われたのかを見ていきたい。研究チームは、完全自動のAIシステムを構築し、三種類の実データでテストを行った。その中でも特に中核となったのが、技術系ニュースサイト「Hacker News」の匿名投稿を対象とした実験だった。彼らは、あるユーザー群の投稿データから、名前、ユーザー名、リンクといった露骨な手がかりをすべて削除した。つまり、一見すると誰のものともわからない、ただの文章の束にしたうえで、その投稿群をAIに渡したのである。そしてAIに、「この匿名ユーザーは、ネット上の公開情報の中の誰に当たるのか」を探させた。照合先として使われたのは、LinkedIn上の実名プロフィールだった。
結果はかなり衝撃的だった。338人のうち、226人が正しく特定された。召回率は67%、精度はおよそ90%。言い換えれば、AIが10人を「この人だ」と判断したら、そのうち約9人は本当に当たっていたということになる。しかも同じデータセットで、従来型の構造化データ照合手法を使った場合の召回率は、わずか0.1%だった。ほとんどゼロと変わらない。
これまで、匿名ユーザーを特定するというのは、誰かが何日もかけて投稿を読み込み、言葉の癖や生活の断片を拾い集め、別サイトの情報と照らし合わせていく、気の遠くなるような作業だった。面倒で、時間がかかり、費用もかさむ。だから多くの人は、自分は安全だと思っていた。研究者たちは、この状態を practical obscurity と呼んでいる。あえて噛み砕いて言えば、あなたが守られていたのは、見つけるのが難しかったからではなく、調べるのが割に合わなかったからだ、ということである。ところが、この論文はその前提がもう崩れていることを示した。
では、AIはどうやって人を“開示”していくのか。本名も住所も明かしていない人間を、なぜ特定できるのか。答えは単純で、そして不気味だ。細かな情報の積み重ねである。研究者たちは、AIによる特定の流れを四つの段階に分けて説明している。まるで、デジタル時代の探偵が、無数の小さな破片を拾い集めて一枚の顔を復元するような手順だ。
第一段階は抽出である。AIは投稿履歴を読み込み、その中に埋もれている「身元の信号」を拾い上げる。たとえば、自分は生物系の研究をしていると書いていたら、その情報は残る。英語の綴りに analysing のような英国式が出てくれば、英連邦圏の可能性が浮かぶ。子どもが秋から学校に通い始めるとぼやいていれば、年齢層や家庭環境の輪郭も見えてくる。一つひとつは取るに足らない雑談に見えても、それらがまとめられることで、半構造化された人物像ができあがっていく。
第二段階は検索だ。こうして整理された人物像を、AIは数理的なベクトルに変換し、膨大な候補データベースの中から「似ている人」を探し始める。やっていることの本質は、検索エンジンが類似する文書を探すのと似ている。ただし対象は文章ではなく、人間である。その結果、何百万という候補の中から、見た目に似た輪郭を持つ人物がいくつも浮かび上がる。
第三段階は推論で、ここが最も重要だ。AIは、匿名アカウントから抽出した人物像と、候補者の公開情報を並べて見比べる。両方とも同じマイナーな学会に言及していないか。同じ映画監督について妙に詳しく語っていないか。言い回しや単語の選び方に、偶然とは思えない共通点はないか。従来のルールベースなシステムでは、この種の意味の近さや癖の一致を扱うのが難しかった。だが大規模言語モデルは、そこを読み取れてしまう。たとえば、別々の投稿で似たような比喩を使っていたり、同じニッチな話題に反応していたりするだけでも、それを一つの手がかりとして扱えるのである。
第四段階は校正、あるいは信頼度の調整だ。AIは各マッチングに対して「どの程度確からしいか」というスコアをつける。自信が持てないものは除外する。そのおかげで、的中率を高く保ちながら候補を絞り込める。

恐ろしいのは、この四段階のどれを単体で見ても、それほど危険な処理には見えないことだ。テキストの要約、意味ベースの検索、情報同士の比較、信頼度の採点。どれも日常的で、合法的で、むしろ便利なAIの使い方にしか見えない。だが、それを一列につなげた瞬間、匿名を剥がすための流れ作業が完成してしまう。研究者の一人、Daniel Palekaはインタビューで印象的なことを語っている。もしあなたの安全が「誰もわざわざ何時間もかけて自分なんか調べないだろう」という前提に支えられているのなら、その前提はもう壊れたのだ、と。

この話は、技術系コミュニティの人間だけに当てはまる特殊な話ではない。研究チームは、もっと日常に近い実験も行っている。たとえば、映画関連の掲示板コミュニティを対象にした実験がそうだ。研究者たちは、映画好きが集まる複数の掲示板からユーザーの投稿履歴を集め、別々の板やスレッドで活動しているアカウント同士を、AIが同一人物として結びつけられるかを調べた。
結果は、映画についてどれだけ語っているかと強く連動していた。映画作品について一作しか触れていないユーザーは、90%の精度条件で識別率3.1%。五作から九作に触れているユーザーでは8.4%。十作以上になると、48.1%にまで跳ね上がった。つまり、ただいくつかの掲示板で好きな映画について語っていただけなのに、ほぼ半分の確率で、あなたの別垢同士がつながってしまうということである。
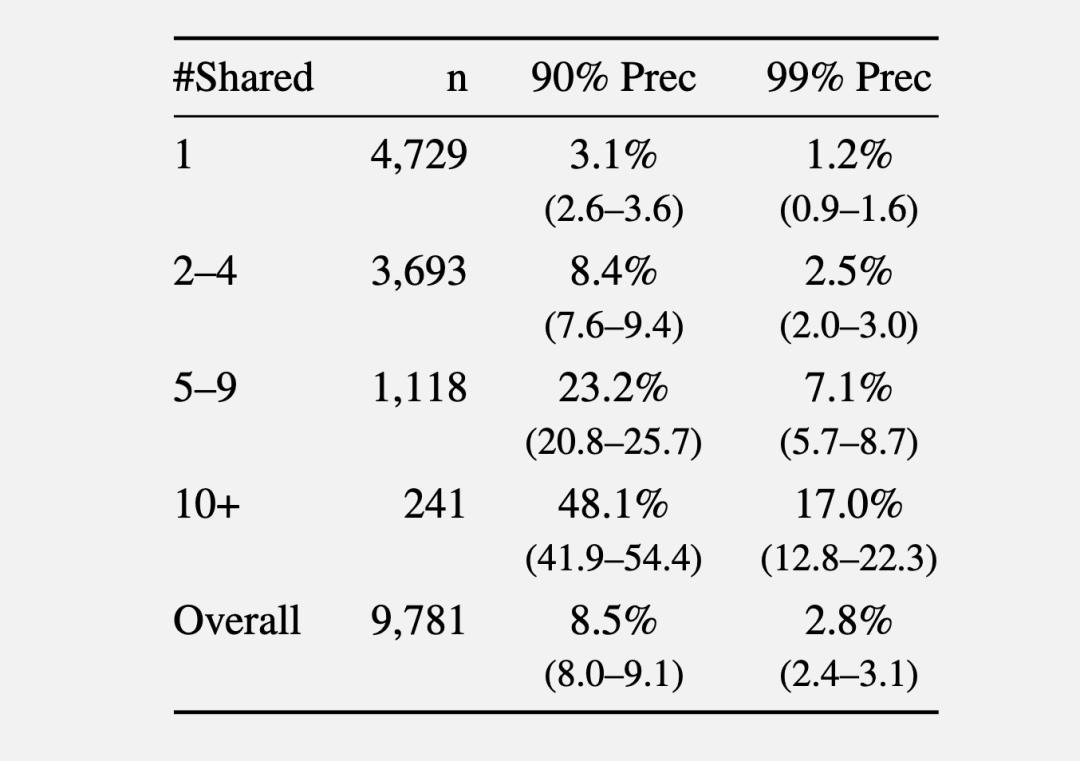
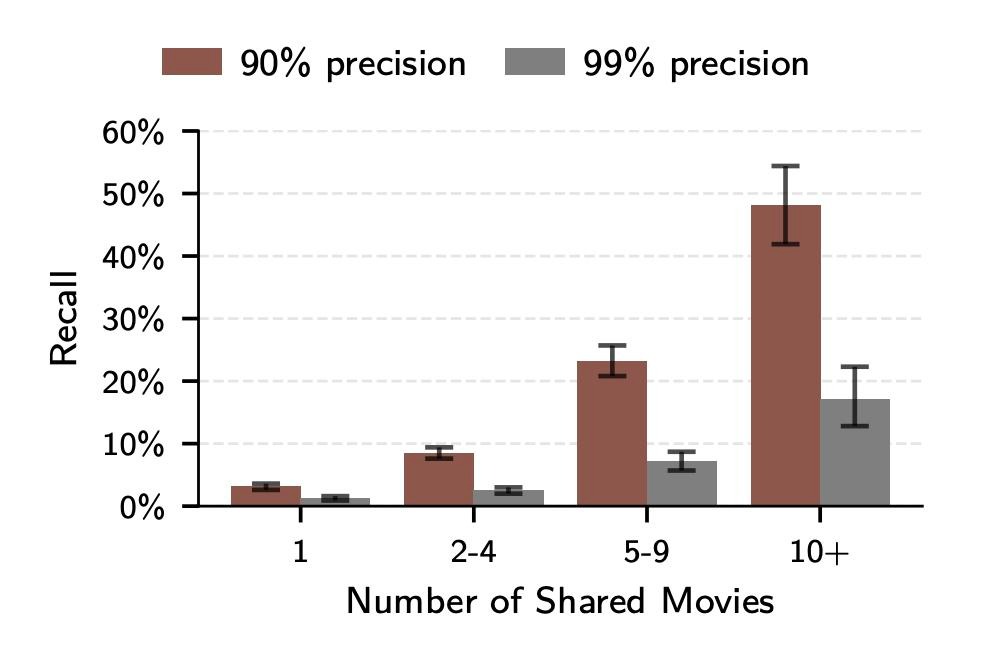
この数字は、いかにも現代的な怖さを持っている。何か極端な個人情報を漏らしたわけではない。ただ感想を書き、好みを語り、繰り返し同じような作品に反応しただけで、人格の輪郭が浮き上がってくる。匿名性を壊すのは、一発の失言ではない。無数の平凡な発言の積み重ねなのだ。
さらに、Anthropicのインタビュー実験はもっと生々しい。Anthropicは以前、社員や外部参加者に向けて、AIツールを普段どう使っているかを尋ねる匿名アンケートを実施していた。研究者たちは、その125件の匿名回答を材料に、回答内容だけを頼りに本人をネット上から探し当てられるかを試した。結果として、9人が特定された。
中でも象徴的なのは、ある回答者のケースである。その人物はアンケートの中で、「自分は生物学分野で働いている」「研究テーマはこれこれだ」「背景には物理学がある」「最近、指導教員とある現象の影響分析について議論した」といった内容を何気なく書いていた。それだけの情報から、AIはまず英国のある大学で博士課程にいる学生へと候補を絞り込み、さらにGitHubの公開リポジトリや bioRxiv のプレプリント情報と突き合わせることで、本人に到達したという。
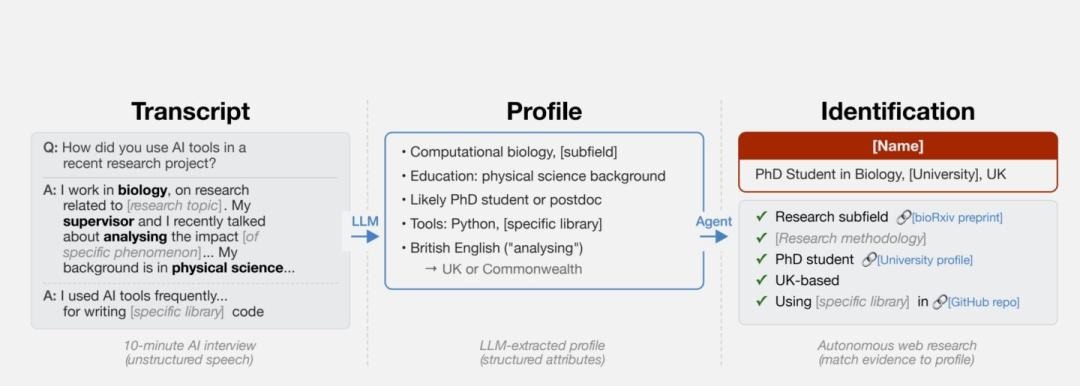
7%という識別率だけを見れば、決して高い数字には映らないかもしれない。だが、ここで特定された人たちは、SNSで長文を日々垂れ流していたわけではない。ただ匿名のアンケートで、仕事について少し話しただけだった。それでも、見つかる時代になっている。論文の共著者Simon Lermenは、「これまでの方法は、似た形式の構造化データ同士を照合する必要があった。だが今は、自由記述の文章から出発して、そこから“あなたは誰か”にまでたどり着ける。これはまったく新しい能力だ」と説明している。
ここで、多くの人はこう思うだろう。AI企業は安全対策をしているはずではないのか、と。モデルには拒否ルールがあり、危険な要求には応じないよう調整されている。それなら、こうした使い方も防げるのではないか、と。だが、この論文が不気味なのは、まさにその期待を崩すところにある。彼らが示したのは、タスクを細かく分解すれば、ほとんどの安全ガードをすり抜けられるという事実だった。
たとえば、いきなりAIに「この匿名ユーザーの正体を突き止めてくれ」と頼めば、モデルはおそらく拒否する。けれども、お願いの形を変えていくと話は違ってくる。「この文章から重要な特徴を要約してください」。これは普通の依頼だ。「この特徴を埋め込みベクトルに変換してください」。これも単なる技術的処理である。「この候補者一覧を、類似度順に並べてください」。推薦アルゴリズムでも使う、ごく一般的な操作だ。「この二人が同一人物である可能性を評価してください」。これも、文章比較や情報整合性のチェックに見える。一つひとつは無害に見える。だが、連ねていけば、それは丸ごと一件の開示作業になってしまう。要約も、意味検索も、類似度ランキングも、AIの基本機能である以上、それ自体を禁止することはできない。つまり、単発の質問に対する拒否設定だけでは、この種の問題を止めきれないのである。
似た構図は、過去にもあった。2008年、Netflixがユーザーの匿名視聴データを公開し、推薦アルゴリズムのコンテストに利用したことがある。すると研究者たちは、そのデータをIMDb上の公開レビューと照合し、実在人物を特定できることを示した。しかも、場合によっては政治的傾向まで見えてしまった。だが、あの時代の攻撃には条件があった。ある程度、形式の近い構造化データ同士が必要だったのである。今は違う。掲示板の短文、知恵袋の回答、Xの愚痴、雑談スレへの書き込み。形式も内容もばらばらな自由文そのものが、すべて攻撃面になる。
電子フロンティア財団(EFF)の上級技術専門家Jacob Hoffman-Andrewsは、「大規模言語モデルは、仕事が速く、しかも退屈しない。だからこそ、理想的なネット探偵になってしまう」と語っている。しかも、これは論文の中だけの話ではない。研究発表の前月には、xAIのチャットボットGrokが、長年芸名で活動してきた米国の成人向けコンテンツ制作者 Siri Dahl に関して、通常の対話の中で本名と自宅住所を出してしまったという騒動も起きていた。本人はその後、SNSで、AIクローラーによって私的情報が二次的に拡散され、ネット全体に撒かれてしまったと訴えている。論文はあくまで学術的な検証である。だが現実は、すでにその先を走り始めている。
では、普通の人間にできることは何か。論文の共著者たちは、いくつか実務的な提案をしている。プラットフォーム側にとって短期的にもっとも有効なのは、データ取得を制限することだという。APIにレート制限を設ける。自動クロールを検知する。大量エクスポートを抑える。脅威を完全に消すことはできなくても、大規模な攻撃を再び「割に合わないもの」に戻すことはできる。
AIサービス提供側にとっては、個々の質問に拒否回答を返すだけでは不十分で、むしろAPIの呼び出しパターンそのものを監視する方が有効だとされる。ある利用者が、まず要約を行い、次に埋め込みを生成し、その後にランキングや照合を繰り返しているなら、その流れ自体がシグナルになる。
そして、個人にできる対策もある。共著者Joshua Swansonは、本当に敏感な内容を発信するなら、完全に新しい垢を使うべきだと助言している。ただし、それだけでは足りない。問題は一つの投稿ではなく、投稿全体を通して滲み出る一貫性にあるからだ。同じ語彙、同じ癖、同じ関心、同じ反応の仕方。それらを跨いで見られた時、人は“誰であるか”を暴かれる。だから、匿名性を守るというのは、単にハンドルネームを変えることではない。運用全体を一つのセキュリティ設計として考えることに近い。プラットフォームごとに文体を変える。興味分野を分散させる。口調や反応パターンを揃えすぎない。少なくとも、無自覚に「同じ自分」をあらゆる場所へ持ち込まないことだ。
もちろん、もっとも単純で荒っぽい方法もある。そもそもあまり書かないこと。あるいは、定期的に古い投稿を消すことだ。論文の締めくくりには、こうした趣旨の警告がある。これまで匿名ユーザーを守っていたのは、「調べるのが面倒すぎる」という事情だった。しかしその盾は、もはや頼りにならない。固定IDで発信している人は、自分の垢がいつ現実の身元と結びつけられてもおかしくないと考えるべきであり、一投稿ごとに、見つかる確率は少しずつ上がっていく。
研究者たちは倫理的配慮から、本当に強い秘匿性を必要とする高リスク層に対する実験は意図的に避け、悪用防止のために技術的詳細の一部も伏せている。それでもなお、彼らは警告を発した。モデルの能力が上がり続ける以上、この種の攻撃は今後さらに簡単になり、さらに安価になっていく、と。
結局のところ、ネット上の匿名性というのは、もともと何か神聖な権利として設計されたものではなかった。誰かが丁寧に守ってくれていたわけでもない。それはただ、人力で暴くには手間がかかりすぎたから、たまたま残されていた灰色の余白にすぎなかった。AIは、そのコストを4ドルまで引き下げつつある。その灰色の余白は、いま、静かに消え始めている。


