
2025年、AI界の風向きを決定づけるかもしれない驚きのニュースが飛び込んできた。「o3がロシア方塊(テトリス)でGeminiを圧倒し、AIゲーム評価で頂点に立った」という話題が、研究者や技術系メディアを中心に爆発的に広まっている。
それは単なるゲーム好きAIの遊戯記録ではない。この勝利の裏には、UCSD(カリフォルニア大学サンディエゴ校)らが打ち出した革新的なAI評価基準『Lmgame Bench』の存在があった。
懐かしのゲーム《ポケモン》《テトリス》《マリオ》《2048》を使って、AIの感知、記憶、推論の3要素を精密に測定しようという壮大な試みが、静かに始まっていたのだ。
ポケモンがAI能力の試金石に? “モラベックのパラドックス”を超えられるか
そもそもなぜ、30年前の『ポケモン 赤・青』が2025年のAIベンチマークとして注目されるのか?
この謎の答えは、かつてAIの巨人たちが提唱した「モラベックのパラドックス」にある。要するに、チェスのような抽象的で論理的な作業はAIにとって比較的簡単だが、人間の子どもでもできる日常的な感知や行動は、AIにとって最も困難というパラドックスだ。
《ポケモン》は、表面上は単純に見えるかもしれないが、綿密な戦略設計、複雑な状態遷移、長期的記憶、環境理解など、人間の総合的な知性を要するゲームである。つまり、「AIがポケモンを自力でクリアできるかどうか」は、まさにその知性の臨界点を問う試金石なのだ。
AnthropicのClaude Opus 4やGoogleのGeminiなど、トップモデルたちが競うようにこのゲームに挑み、「ジムリーダー撃破」や「バッジ獲得」を実績として誇示しているのも、その意味で納得がいく。
バラバラだった評価方法を統一:『Lmgame Bench』の登場
しかし、ポケモンに挑むAIたちの戦績はバラバラで、「何をもって成功とするのか」という基準が不透明だった。これでは比較評価が難しい。たとえば、あるモデルが35,000アクションで電気ジムに到達したとしても、その「アクション」の定義が曖昧では他モデルと比較にならない。
こうした混乱を解決すべく、UCSDなどの研究チームが開発したのが、Lmgame Benchである。
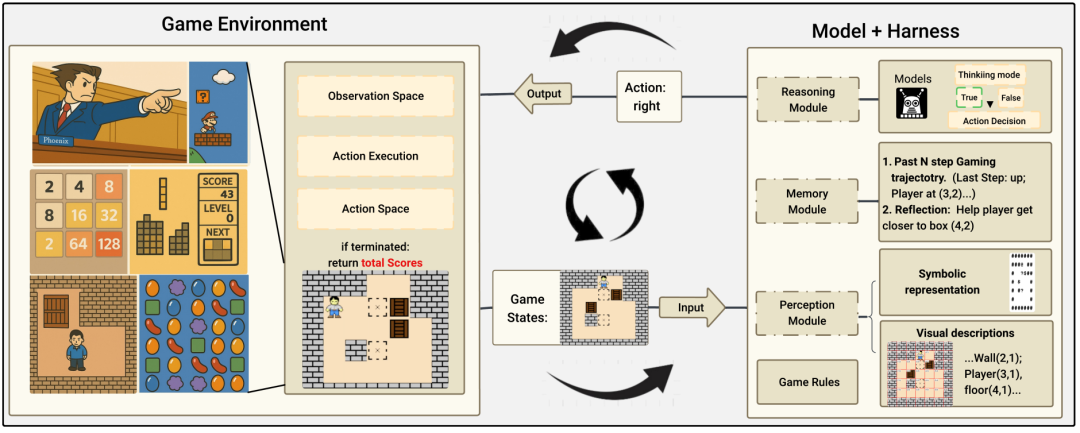
これは、ゲームという複雑な環境下でLLM(大規模言語モデル)の知的能力をモジュール単位で測定する統一基準だ。ポケモンだけでなく、複数のクラシックゲームを用いて、感知(Perception)、記憶(Memory)、推論(Reasoning)という3つの知的機能を分解・評価する。

感知・記憶・推論の三位一体:各モジュールの精緻な設計
Lmgame Benchでは、AIが単にゲームを操作するのではなく、以下の3つのモジュールに基づいて行動する。
感知モジュール:
スクリーンショットやUI要素を構造化されたテキストに変換。AIの視覚的弱点を補い、状態の誤認を減らす。
記憶モジュール:
最近の状態・行動・反省ログを保存し、次の行動選択に生かす。長期的な計画や試行錯誤に不可欠な仕組みだ。
推論モジュール:
感知・記憶の両情報を統合し、「長鎖型思考(Chain-of-Thought)」による論理推論を展開する。

テスト対象ゲームと評価方式:ただの遊びじゃない!
Lmgame Benchが選定したゲームは、簡単すぎず難しすぎず、AIの知性を測るのに“ちょうどいい”バランスを持つものが多い。
たとえば《2048》では、ボードが停滞するまでに得られた合計得点でモデルを評価。《推箱子(Sokoban)》では、どれだけの箱を正しくゴールに運んだかがスコアになる。《マリオ》では横方向の移動距離が評価軸だ。

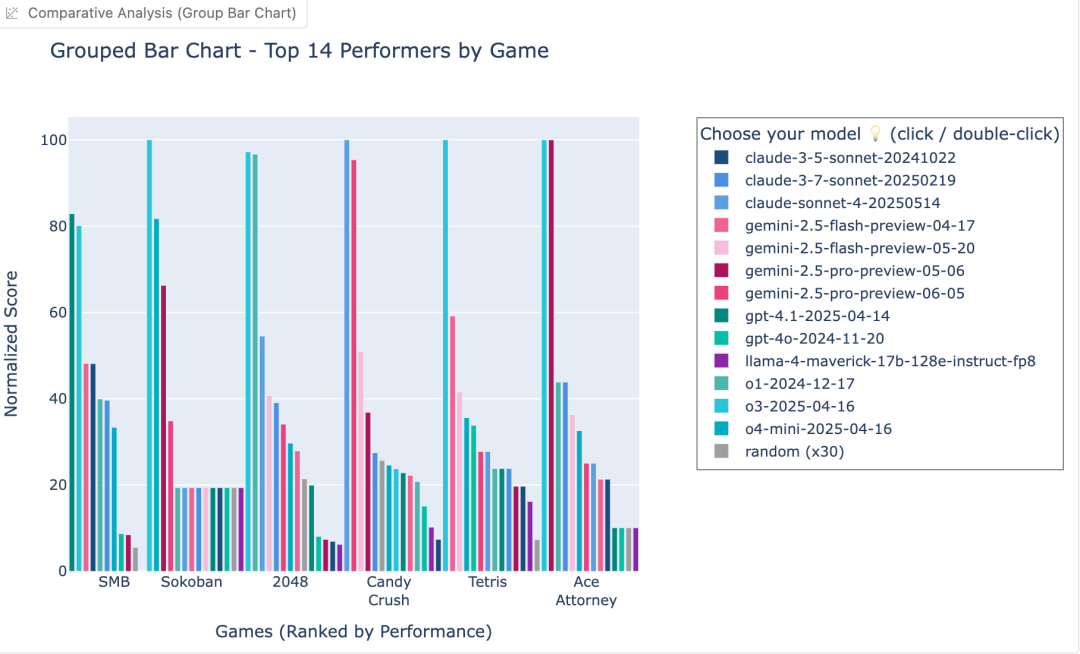
また、《テトリス》では消したライン数×10に加え、積み上げたブロック数が加算スコアとなる。ここでo3は圧倒的なスコアを出し、Geminiを完全に凌駕した。

o3が圧倒的首位へ、ただし「完璧」ではない
現時点のランキングでは、「o3」が2048、推箱子、テトリスの3つを完全制覇。感知精度、空間推理力、長期的視野で他モデルを圧倒する。
しかし意外なことに、「キャンディークラッシュ系」のような軽めのゲームでは得点が伸び悩む。これは、単純な反応速度や行動最適化において、o3の判断ロジックがまだ改善の余地を残していることを示唆している。
評価環境にも標準化:Gym APIによる公平性の確保
多くのAI評価系統では、スクリーンショットからの観察や、特定のハードウェア環境への依存があり、比較が不公平になることも多かった。
これに対してLmgame Benchは、OpenAI Gym風のAPIを導入し、モデルとゲーム環境のインタラクションを完全標準化。これにより、誰でも同一条件下でのテストが可能になり、結果の再現性と透明性が大幅に向上した。

ゲームはAI評価の「未来」か
一見、娯楽に過ぎないゲームだが、その複雑な状況認識・計画・応答力は、実世界の問題解決能力に直結する。かつて人間が楽しむために作られたゲームが、今やAIの「知性」を測る高度なツールに進化しているのだ。
さらにLmgame Benchは、現在のクラシックゲーム評価にとどまらず、今後は3Aタイトルなどを含めた拡張性あるフレームワークへと進化する可能性も秘めている。

結びに:AIが“賢い”とはどういうことか?
プログラムを書く、論理問題を解く——確かにAIの得意分野だ。しかし、複雑で変化する環境下で、自律的に判断し、適切に行動できることこそ、本当の「知性」ではないか。
UCSDのLmgame Benchが提示したこの新しい基準は、まさにAIの“知性の本質”を暴き出すものである。そしてそれは、単に点数を競うだけでなく、AIが人間社会にどのように適応していくかを測る鏡でもある。
AIが「ポケモンをクリアした」と聞いて笑っている場合ではない。このゲームの中に、未来のインテリジェンスの輪郭があるのかもしれないのだから。


